Better ECS autoscaling with capacity providers
22 May 2021What is ECS?
Amazon Elastic Container Service (ECS) is a fully managed container orchestration service.
ECS provides an easy and scalable way to deploy containers to cloud. ECS containers can be run on either EC2 if you are looking to manage your own underlying infrastructure or AWS Fargate if you are looking to move to a serverless approach.
An ECS cluster consists of mutiple services, which in turn are copies of a file (task definition) which run as tasks on the underlying infrastructure.
A task definition is like a docker compose file which gives all the available options of a simple docker compose file and some extra features provided by AWS, which are integrated with other AWS services, for example, aws-logs driver for pushing logs to cloudwatch, systems manager to store sensitive variables which are injected only at runtime and many more.
In a typical task definition, there are a lot of fields required but we will focus on two most important parameters:
- CPU Units (A container instance has 1024 cpu units for every CPU core)
- Hard and soft memory limits
These two parameters are required when a task (docker container) is placed on the underlying infrastructure.
Scenario
Let’s consider a simple ECS cluster with 2 services, alpha and beta.
- alpha service requires 1024 CPU units and 2048MB soft limit Memory.
- beta service requires 512 CPU units and 512MB soft limit Memory, and 1024MB Hard limit Memory.
For the scope of this article lets consider the underlying infrastructure is EC2, which means we have to manage scaling and instances on our own.
When cluster was launched and services were started with 1 task each, we had a single EC2 instance (say t2.medium, which has 2 vCPU and 4 GiB Memory). Our tasks were perfectly placed side by side with the instance still sparing 512 units CPU and 1024 Memory.
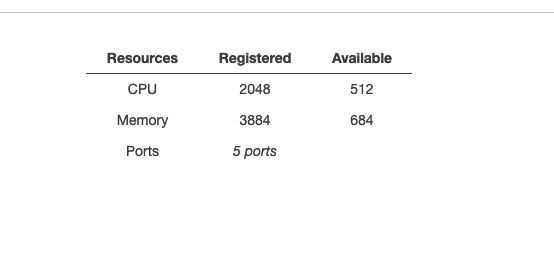
Below image shows an example registered container instance in an ECS cluster with some memory and CPU reserved.
Normal Autoscaling
When an ECS cluster is created (when not choosing an empty cluster option) a cloudformation template and an autoscaling group are created. This autoscaling group can be used to trigger scaling to add extra EC2 instances to the cluster on cluster memory usage or other parameters.
This is all good, but a problem arises in case a new task is to be placed in the cluster, but no container instances match the requirements!
For example in our case, say if we were to deploy another task for alpha service, we can see that the only container instance attached doesn’t have enough resources for the task to be placed on it, and since no CPU or memory thresholds are crossed so the default autoscaling group won’t get triggered, and our desire to start another task remains stuck!
All hail capacity providers
Capacity providers see our request of starting a new task of alpha service as units, which means that we are requesting x% more capacity. A capacity provider uses an auto scaling group to fulfill the required demand of the service or the cluster.
A capacity provider is attached to a cluster and is sort of an extension over autoscaling group (ASG). We first create an ASG with our requirements, and then create a capacity provider from ECS console.

We attach our asg to capacity provider and set the target capacity as 100% so that our instances are fully used.
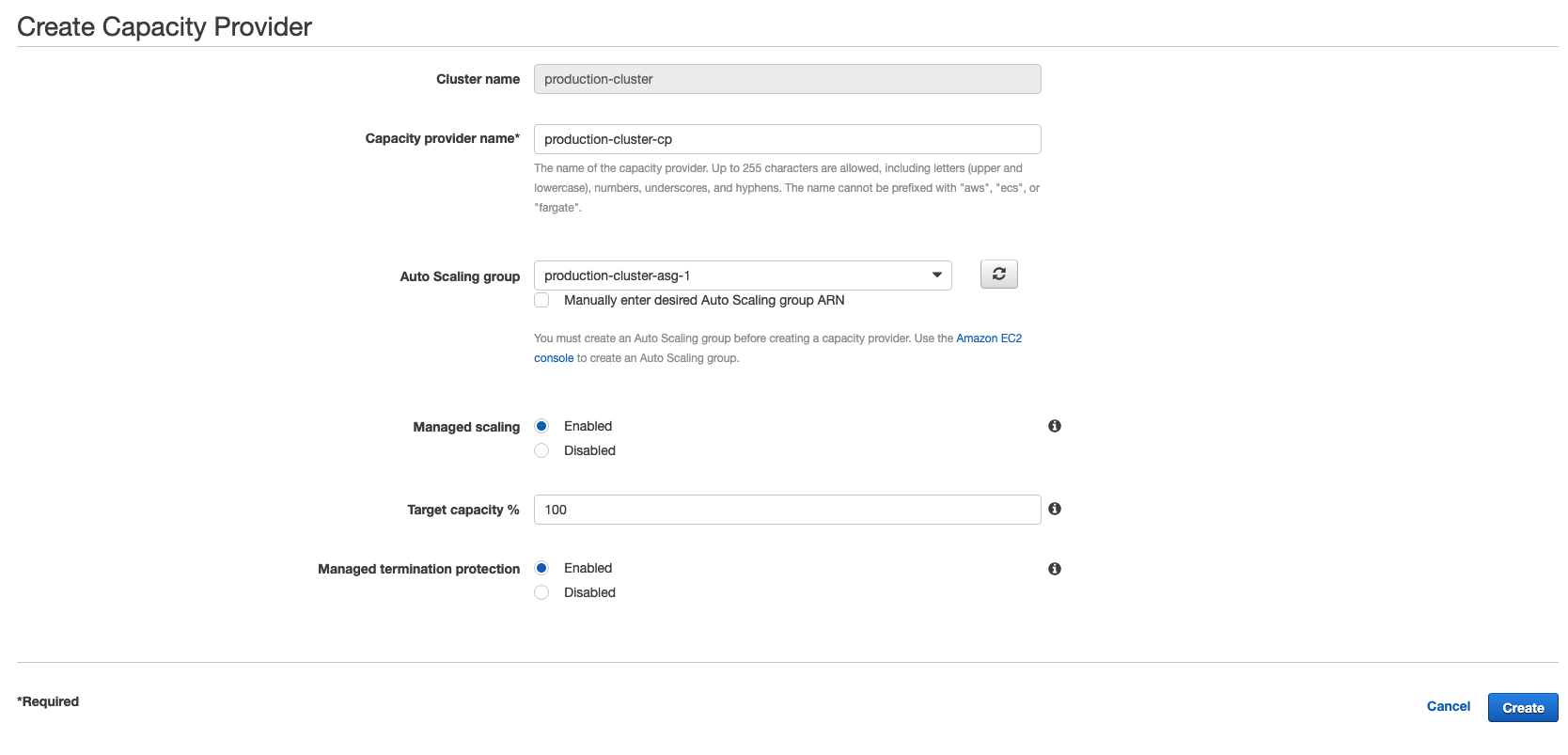
We then attach this capacity provider to our alpha service and restart it. When x amount of CPU units or memory is requested, capacity provider will start the required number of EC2 instances (type and cost defined in ASG) to fulfill that demand, thus giving us dynamic scaling that we require.
New Deployments
Capacity provider not only helps in autoscaling but in deployments as well.
Say our alpha service was configured for deployment strategy in which minimum health percent is 100 and max is 200. Here min health percentage 100 means that say if x tasks of a service were running and now we deploy a new task definition, ECS will start x more tasks, making total 2x tasks, will monitor the new ones for some time, if they don’t crash then the old x tasks are gracefully stopped.
Now in this case, we can easily add new instances using capacity providers!
Cost optimizations
Now that we have seen how to attach a capacity provider to a service, what we have seen applies only to either on-demand or on spot instances.
Recently I have been working on a use case where we were to scale a service based on a cloudwatch metric that was published from a third party service, and since the threshold was met for like only every other hour or so, using on-demand instances for these burst scaling was proving to be costly.
Spot instances to the rescue!
Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud!
These instances are upto 90% discounted, with a slight drawback that these can be taken back if your bid price is lower that that of any other customer. But generally these instances work and we leveraged this heavily to bring down our costs!
Configuring the ECS service
Though ASG provides an option to launch spot instances along with on-demand instances.
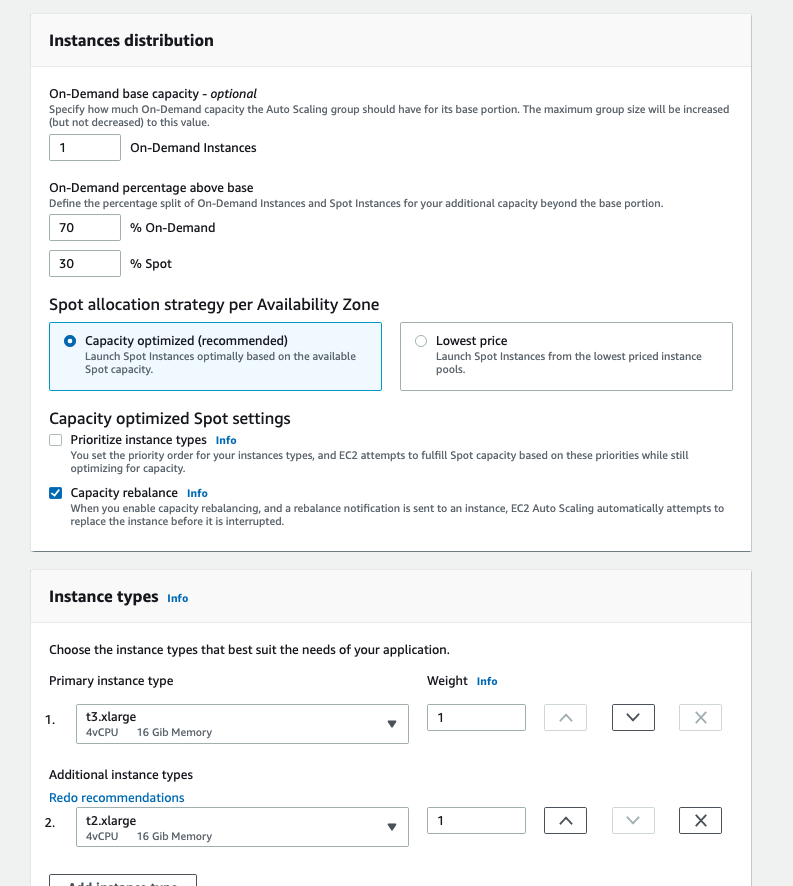
There are a bunch of options in the above images, focus on the instance distribution, where we can define percent of instance launch types.
A problem with using this approach was that, we wanted to run a fixed 2 on-demand instances at all times, but only add spot instances when burst traffic occurred. Using this won’t help as asg might stop the on-demand instance after the peak has gone and all we are left with are spot instances, which are less reliable as compared to on-demand instances. So, we leveraged capacity providers to maximise the spot usage.
Remember how we added a capacity provider to a service, an interesting fact is that we can attach mutiple capacity providers to a service with different weights and base!
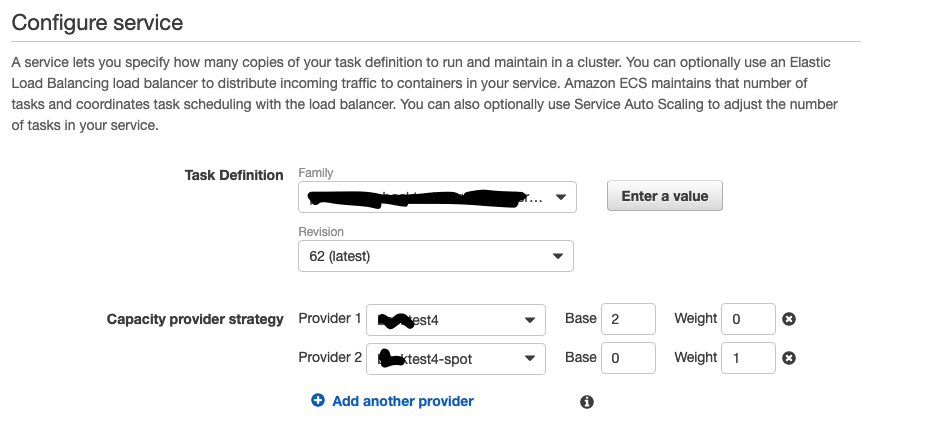
We have two capacity providers
- test - Only has on-demand instances
- test-spot - Only has spot instances
Under capacity provider strategy,
- base, means number of instances to run from this capacity provider
- weight, means weightage to be given to capacity provider when adding new instances
So, for the test capacity provider we set base 2 as we wanted 2 on-demand instances to be running at all times, and for test-spot we set base as 0, because we don’t want any all the time running spot instances.
Since the weight of test capacity provider is 0, when autoscaling kicks in this capacity provider is ignored and instances are attached only to test-spot capacity provider. Voila!
This saves us a significant amount, by just using spot instances!
Capacity provider is an awesome tool, which can be used for preferential autoscaling, scaling across multiple availability zones and many more…