Why is Zookeeper being removed from Kafka?
04 Jan 2025If you need a primer on Apache Kafka, I recommend reading Kafka 101
Kafka needed Zookeeper until the community decided to implement their self-managed solution, KIP-500. The idea was to implement a self-managed metadata Quorum based on Raft protocol.
Kafka uses ZooKeeper to store its metadata about partitions and brokers and elect a broker to be the Kafka Controller. Zookeeper had to be deployed as a three-node cluster separately to manage the main Kafka Cluster. Whenever any update in metadata needs to be transmitted from the Controller Node to other nodes, it might be possible for these changes to diverge from what is stored in Zk as compared to what is stored in the Controller’s memory.
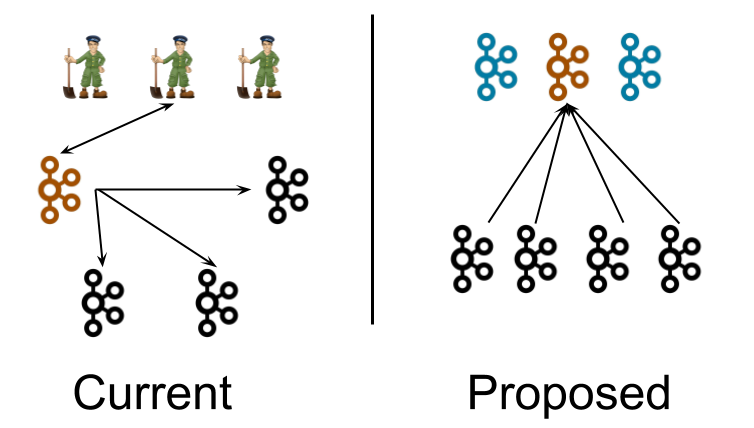
In the above figure, on the left side, the orange node loads its state from Zookeeper after being elected controller. All the brokers interact with Zookeeper during their lifetime, pushing and pulling changes.
On the right side, we see the Zookeeper nodes being replaced by 3 Kafka Controller nodes which now manage the cluster.
Zookeeper is a separate system with entirely different deployment, configuration, and management methods. Hence, unifying the Metadata store into one will reduce mistakes and misconfigurations and greatly simplify the deployment process.
Several KIPs discuss the Raft Protocol in great detail (as mentioned in References.).
Kafka Versions to Remove Zookeeper
- 3.3 -> KRaft mode declared production-ready
- 3.4 -> Migration from ZK mode supported as Early Access (EA)
- 3.5 -> ZK mode deprecated
- 4.0 -> Only KRaft mode supported